
Application
-
A voice of a speaking person is usually surrounded by unrelated sounds (background noise) which make it hard to understand him. In case of multiple speaker, the noise is hard to be aligned
-
Previous audio-visual approaches attempted to learn the statistics of the noise from periods when the face was static, and remove this noise from the incoming sound.
Our Innovation
A novel audio-visual approach that enhances the speaker’s voice based on its correlation with his mouth and face movements.
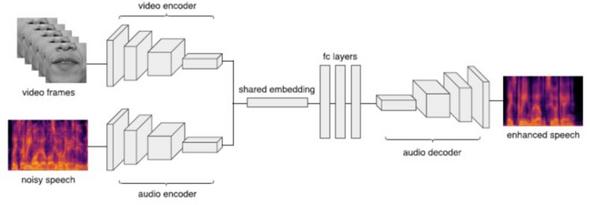
Figure 1 Illustration of our encoder-decoder model architecture. A sequence of 5 video frames centered on the mouth region is fed into a convolutional neural network creating a video encoding. The corresponding spectrogram of the noisy speech is encoded in a similar fashion into an audio encoding. A single shared embedding is obtained by concatenating the video and audio encodings, and is fed into 3 consecutive fully-connected layers. Finally, a spectrogram of the enhanced speech is decoded using an audio decoder.
Advantages
-
Enhances the audio signal of a talking person by removing the background noise
-
Separates the voices of two or more talking persons based on a synchronized video recording of their faces while talking.
-
Could be combined with existing audio-visual approaches
Technology
-
Predicts the person’s speech based on the lips and face movement to filter the original incoming sound and removes unrelated frequency components.
-
Enhances the speaking person’s voice by analyzing its facial movement as observed in the video, and producing voice that, during speaking periods, has better correspondence to the speaking person’s articulatory motion as seen in the video.
-
Several sound encoding methods are being used as well to optimize performance.
Opportunity
-
Unique application for smart mobiles and video camera
-
Video conference improvement
-
Video chats improvement
-
Hearing aid improvement
Related publications https://arxiv.org/pdf/1711.08789.pdf
PATENT STATUS
Granted US 10,475,465; US 10,777,215
