
| Category | Machine Learning, AI |
| Keywords | Data Labelling, Ballpark Learning |
Application
In many classification problems, labeled instances are often difficult, expensive, or time-consuming to obtain. Unlabeled instances, on the other hand, are easier to obtain, but it is harder to use them for classification.
Our Innovation
The researchers proposed a new learning setting in which few, if any, labeled instances exist. In this setting, they received sets (“bags”) of unlabeled instances with constraints on label proportions, and relaxed the unrealistic assumption of known label proportions. The researchers formalized the problem as a bi-convex optimization problem and proposed an efficient algorithm, including a novel form of cross-validation. The developed classifier performs well using very little input. They also demonstrated that the algorithm could guide exploratory classifications. The group has empirically studied the behavior of our algorithm under different types of constraints.
Our algorithm is designed to use when human labeling resources are scarce. Despite the simplicity of our methods, we achieved high accuracy with a very modest amount of input, and considerably loose (or unspecified) constraints.
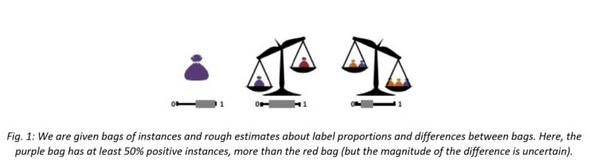
Opportunity
One direction for future work is to analyze and understand, for instance, how constraint tightness affects performance, obtain convergence guarantees, and provide generalization error bounds. This, in turn, could perhaps lead to better algorithms with theoretical justifications. Finally, the relative-proportions setting is very natural, and can be found in various domains. We believe that this line of work will have interesting implications regarding privacy and anonymization of data – in particular, the amount of information one can recover using only weak, aggregated signals.
