
| Category | Computer Science |
| Keywords | NLP |
Application
When performing localization tasks for products, there is a need to translate a large quantity of text. Automatic translation services are available, but the user will not be able to predict the quality of the content.
Is it possible to estimate the level of difficulty to translate a specific sentence, before undertaking the process? This information is critical for companies and individuals when it comes to time and cost efficiency.
While there is an increasing amount of automated translation services, there is no service providing quality indicators for the consumers. Often this leads to the consumer spending time and effort on human annotators or an automatic Quality Estimation (QE) system. And, even if these resources are utilized, there is no guarantee of quality assurance, often ending with delays, overbudgeting and additional unforeseen issues. This results in an additional step of hiring human translators to correctly translate the material.
Our Innovation
The researchers have developed a PreQuEL focusing on linguistic features of source texts. The model estimates the sentences in terms of semantic and syntactic structures for the language pairs that make it easy or difficult to translate. This approach potentially saves resources by predicting a sentences’ translation success, prior to the actual process. The decision between the automatic route and the more expensive alternative of hiring human translators can be advised by a PreQuEL model, before investing the resources and time.
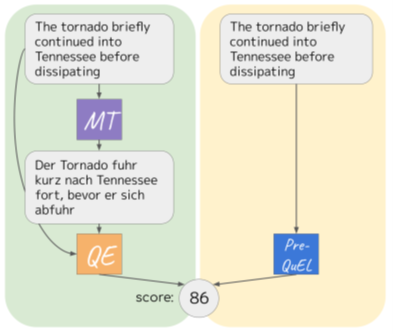
The dataset for the task is composed of data for six language pairs, of which we use the high-resource languages English-German (en-de) and English-Chinese (en-zh) and medium resource pair Estonian-English (et-en). Each language pair has 7K,1K,1K sentence pairs in the training, development and test sets respectively. Translations were produced with a state-of-the-art MT model built using the Fairseq a sequence modeling toolkit.
Opportunity
The research and the code are available as open source. The group is interested to collaborate with industrial companies and support commercial implementations.
https://arxiv.org/abs/2205.09178
Code and data are available in: https://github.com/shachardon/PreQuEL
